La fabrication du consentement v2 — Des médias de masse aux algorithmes prédictifs
En 1988, Noam Chomsky et Edward Herman publient Manufacturing Consent. Leur thèse centrale : dans les démocraties libérales, le consentement populaire n’est pas obtenu par la force mais par un filtrage systémique de l’information. Trente-huit ans plus tard, les cinq filtres qu’ils identifiaient n’ont pas disparu. Ils se sont numérisés, automatisés et individualisés. Ce qui était un mécanisme industriel est devenu un mécanisme algorithmique — plus granulaire, plus rapide, et considérablement plus difficile à percevoir.
Cet article remonte la chaîne, du cadre théorique initial aux opérations documentées de Cambridge Analytica, en passant par les preuves internes de Facebook, les outils actuels de manipulation synthétique, les cas européens de surveillance, et la position singulière de Palantir dans l’architecture mondiale de la donnée. Chaque section distingue les faits vérifiables des hypothèses étayées. La conclusion articule trois niveaux : comprendre le mécanisme, s’en défendre individuellement, et en tirer des implications d’investissement.
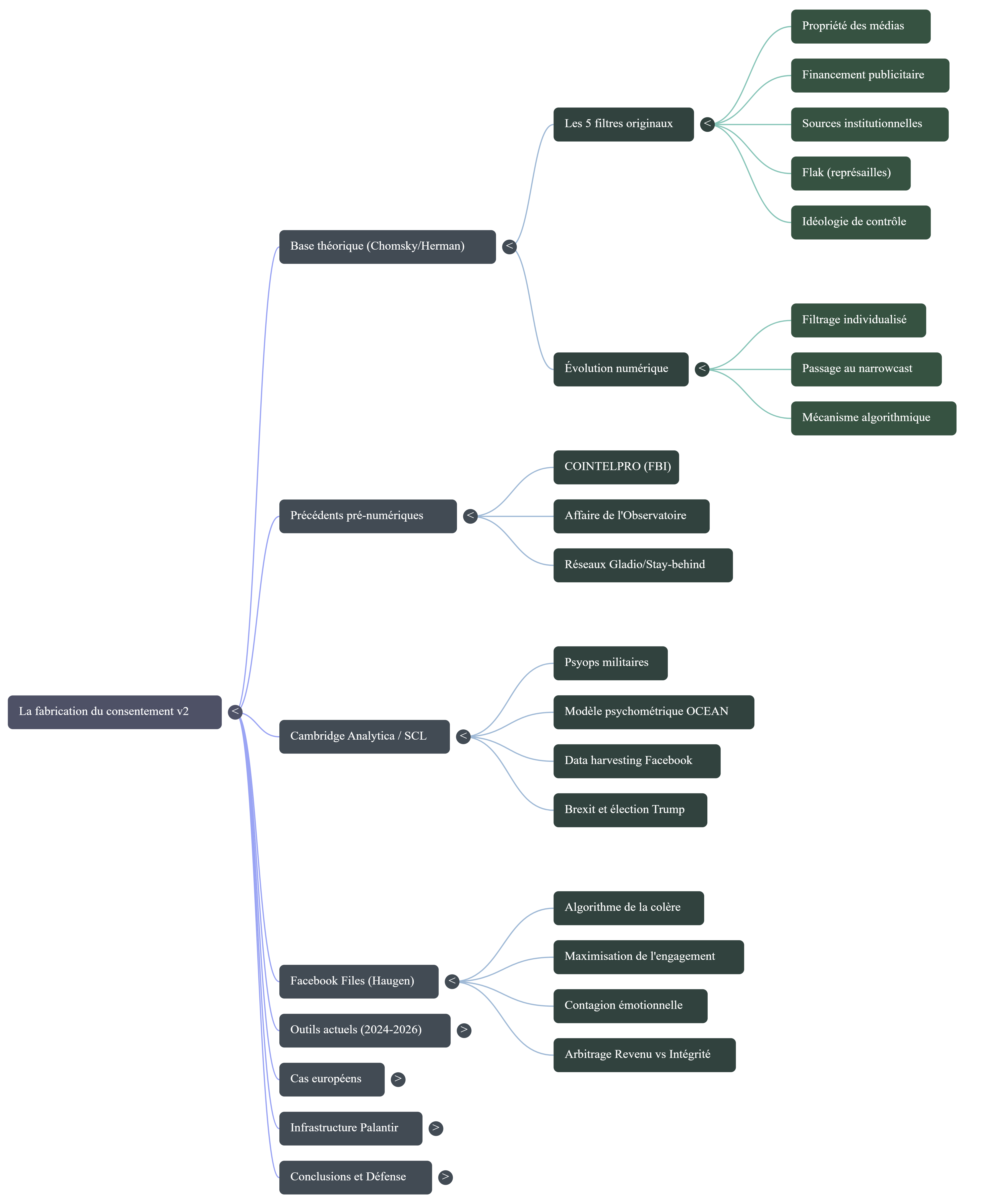
1. Base théorique — Chomsky/Herman et les cinq filtres
Le modèle de propagande de Chomsky et Herman repose sur cinq filtres qui structurent la production de l’information dans les démocraties de marché, sans nécessiter de conspiration centralisée. Chaque filtre opère comme un mécanisme de sélection naturelle : les contenus qui passent tous les filtres atteignent le public ; les autres disparaissent.
Les cinq filtres originaux
1. La propriété des médias. Les organes de presse appartiennent à des conglomérats dont les intérêts économiques conditionnent la ligne éditoriale. En 1988, c’était General Electric, Westinghouse, Disney. En 2026, c’est Alphabet, Meta, Amazon — les plateformes qui contrôlent simultanément la distribution et la monétisation de l’information.
2. Le financement publicitaire. Les annonceurs ne censurent pas directement, mais leur pouvoir économique filtre les contenus qui les défavorisent. Ce filtre s’est hypertrophié : le modèle publicitaire programmatique représente aujourd’hui plus de 600 milliards de dollars annuels. L’algorithme ne sélectionne plus un journal, il sélectionne chaque impression individuelle.
3. La dépendance aux sources institutionnelles. Gouvernements, entreprises, think tanks fournissent l’essentiel de la matière brute du journalisme. Ce filtre reste intact : les relations publiques emploient aujourd’hui quatre à six professionnels pour chaque journaliste dans les pays de l’OCDE.
4. Le « flak » — les représailles organisées. Campagnes de pression, poursuites judiciaires, lobbying législatif contre les médias déviants. En 2026, le flak s’est automatisé : astroturfing sur X, brigading organisé, SLAPP lawsuits — le coût de production du flak a chuté tandis que son volume a explosé.
5. L’idéologie de contrôle. En 1988, l’anticommunisme. Aujourd’hui, les épouvantails idéologiques varient selon les marchés — terrorisme, populisme, désinformation — mais la fonction reste identique : créer un cadre binaire qui disqualifie par défaut les positions hors-consensus.
Ce qui a changé
Le modèle de 1988 décrivait un filtrage industriel, opérant au niveau des organisations. La transformation majeure depuis est l’individualisation du filtrage. Les cinq filtres opèrent désormais au niveau de chaque utilisateur, en temps réel, optimisés par des systèmes d’apprentissage dont même les opérateurs ne comprennent pas toujours les mécanismes de sélection. Le passage d’un modèle broadcast (un message, des millions de récepteurs) à un modèle narrowcast (des millions de messages personnalisés) ne change pas la nature du filtrage — il en augmente la résolution.
2. Précédents pré-numériques — L’ingénierie du consentement avant l’internet
L’idée que la manipulation de l’opinion publique est un phénomène numérique est une illusion d’optique. Les techniques existaient bien avant les algorithmes. Quelques cas documentés permettent de calibrer l’échelle.
COINTELPRO (1956-1971)
Le programme de contre-intelligence du FBI, déclassifié en 1971 suite au cambriolage des archives de Media, Pennsylvanie, visait des organisations politiques domestiques — du Parti communiste américain aux Black Panthers, en passant par le mouvement des droits civiques de Martin Luther King. Les techniques documentées incluaient : infiltration d’agents provocateurs, création de faux documents pour provoquer des dissensions internes, campagnes de désinformation via des lettres anonymes, et pression sur les employeurs des militants ciblés. Le programme a opéré pendant quinze ans avant d’être découvert — non par un mécanisme de contrôle institutionnel, mais par un vol de documents.
Point clé : la manipulation structurelle ne nécessite pas de technologie sophistiquée. Elle nécessite un accès à l’information, une compréhension des dynamiques sociales des cibles, et l’absence de supervision externe. Ces trois conditions sont aujourd’hui réunies à une échelle sans précédent.
L’affaire de l’Observatoire (1959)
En France, le faux attentat de l’Observatoire, orchestré par François Mitterrand lui-même contre sa propre personne en 1959, illustre un autre registre de fabrication : la construction d’événements destinés à modifier la perception publique d’un acteur politique. L’opération — mitterrandienne et non étatique — démontre que la capacité de manipuler la narration n’est pas réservée aux appareils de renseignement. Elle est accessible à tout acteur disposant d’un accès médiatique et d’une compréhension des dynamiques narratives.
Opérations Gladio et stay-behind (1956-1990)
Le réseau stay-behind de l’OTAN, dont l’existence a été officiellement confirmée par le Premier ministre italien Giulio Andreotti en 1990, illustre la dimension européenne de la manipulation structurelle de la guerre froide. Documenté par le rapport du Parlement européen de novembre 1990, le réseau opérait dans au moins quatorze pays européens. L’implication de certaines structures stay-behind dans des opérations de tension — notamment en Italie (stratégie de la tension, attentats de la Piazza Fontana en 1969 à Bologne en 1980) — reste un sujet de débat historiographique, bien que les enquêtes parlementaires italiennes aient établi des liens entre certains opérateurs stay-behind et des actes de violence attribués initialement à l’extrême gauche.
Ces précédents établissent un fait structurel : la manipulation organisée de l’opinion publique est une constante des démocraties libérales, pas une anomalie de l’ère numérique. Le numérique n’a pas inventé le problème — il en a transformé l’échelle, la vitesse et la granularité.
3. Cambridge Analytica / SCL Group — La psychométrie comme arme politique
Origines : SCL Group, du psyops militaire au consulting électoral
Cambridge Analytica n’était pas une startup. C’était la branche électorale américaine d’un groupe britannique, Strategic Communication Laboratories (SCL), fondé dans les années 1990 et spécialisé en opérations d’influence psychologique. SCL avait travaillé pour le ministère de la Défense britannique, l’OTAN, l’armée américaine — notamment en Afghanistan et en Irak — avec des techniques de « target audience analysis » qui, selon d’anciens employés, étaient autrefois classifiées comme matériel d’exportation contrôlée par le gouvernement britannique.
L’ancien directeur du développement de Cambridge Analytica, Brittany Kaiser, a explicitement déclaré que les méthodes utilisées en politique étaient directement issues du travail de défense : les mêmes techniques de science sociale et d’analyse de données déployées en contre-terrorisme étaient adaptées aux élections civiles. Le groupe SCL se targuait d’avoir opéré dans plus de soixante pays. Des documents internes montrent des opérations documentées au Kenya (47 000 répondants pour un profilage psychosocial), en Colombie, au Nigeria, à Trinité-et-Tobago, au Yémen (« Project Titania », une opération de surveillance psychologique pour le compte d’un contractant militaire américain), et en Lettonie (exacerbation de tensions ethniques pour favoriser un client politique).
Le modèle OCEAN et le data harvesting Facebook
Le vecteur technique de Cambridge Analytica reposait sur le modèle OCEAN (Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism), dit « Big Five », appliqué à des données Facebook récoltées sans le consentement éclairé des utilisateurs. Via une application de quiz académique développée par le chercheur Aleksandr Kogan, Cambridge Analytica a accédé aux données de plus de 80 millions de profils Facebook — non seulement ceux qui avaient rempli le quiz, mais ceux de l’intégralité de leurs réseaux d’amis.
Le profilage psychographique permettait de segmenter l’électorat non par démographie classique (âge, revenu, géographie) mais par profil psychologique. La promesse était de cibler chaque individu avec le message calibré pour ses vulnérabilités spécifiques. Selon le lanceur d’alerte Christopher Wylie, qui avait apporté l’expertise data science à Cambridge Analytica : plutôt que de la publicité politique classique, l’objectif était de créer les conditions dans lesquelles les gens seraient plus susceptibles de faire ce qu’on voulait qu’ils fassent.
Brexit et Trump 2016 : déploiement grandeur nature
Cambridge Analytica a été déployée sur deux opérations majeures en 2016. Pour le référendum britannique, la connexion passait par AggregateIQ, société canadienne décrite par d’anciens employés comme le « back office » de Cambridge Analytica. AggregateIQ a reçu des fonds substantiels de la campagne Vote Leave — un point qui a donné lieu à des enquêtes de la Commission électorale britannique.
Pour la campagne Trump, Cambridge Analytica a collecté au minimum 6 millions de dollars selon les déclarations fédérales. Les registres montrent que la société a fourni du data modeling et du polling qui ont mis en évidence la force de Trump dans le Midwest industriel, contribuant à orienter la stratégie de campagne vers ces États décisifs.
Dissolution et continuation
Après l’explosion du scandale en 2018, Cambridge Analytica et SCL Elections ont été mises en liquidation judiciaire. Mais une nouvelle entité, Emerdata Limited, a été constituée dans les mêmes bureaux, avec la même direction et les mêmes investisseurs. Les analystes qui ont suivi la structure corporate ont noté que cette temporalité n’était pas un hasard : les techniques, les données et le savoir-faire ne meurent pas avec la dissolution d’une entreprise. Ils migrent.
Fait vs. hypothèse. Fait documenté : SCL/Cambridge Analytica a récolté les données de 80+ millions d’utilisateurs Facebook, a opéré des campagnes d’influence dans 60+ pays, et a été financée par le milliardaire Robert Mercer avec 15 millions de dollars d’investissement initial. Hypothèse étayée : l’efficacité réelle du micro-ciblage psychographique sur le résultat de l’élection 2016 ou du Brexit reste débattue dans la littérature académique. Les recherches récentes (Hackenburg & Margetts, PNAS 2024) suggèrent que les messages générés par LLM sont persuasifs en agrégat, mais que le micro-ciblage personnalisé n’offre pas d’avantage statistiquement significatif par rapport à des messages non ciblés. L’outil existait, son efficacité marginale exacte reste un objet de recherche.
4. Facebook Files / Frances Haugen — Quand la plateforme optimise le conflit
Les documents internes
En octobre 2021, Frances Haugen, ancienne product manager chez Facebook spécialisée dans les algorithmes, a livré au Wall Street Journal puis au Congrès américain des milliers de documents internes. Ces documents constituaient la première preuve interne qu’une plateforme majeure connaissait les effets délétères de ses algorithmes et choisissait délibérément de ne pas les corriger.
Le fait central, documenté par les fichiers internes : en 2017, Facebook a modifié son algorithme de News Feed pour que les réactions emoji (« angry », « love », « sad », « wow ») comptent cinq fois plus qu’un simple « like » dans le classement des contenus. L’objectif était d’augmenter l’engagement. Un employé de Facebook avait averti en interne que cette pondération risquait de surreprésenter les contenus controversés dans le fil d’actualité. L’avertissement s’est vérifié : les data scientists de l’entreprise ont ensuite constaté que les posts suscitant des réactions « angry » avaient une probabilité plus élevée de contenir de la désinformation et du contenu de faible qualité.
L’algorithme de la colère
Les documents montrent que les partis politiques de plusieurs pays — Pologne, Espagne, Taiwan, Inde — se sont plaints à Facebook que l’algorithme, en promouvant le contenu à fort engagement, amplifiait les messages négatifs et la polarisation. Un data scientist de Facebook a écrit en 2019 dans un rapport interne qu’un effet secondaire de la plateforme était que le contenu nuisible et désinformatif pouvait devenir viral avant que les systèmes ne puissent le détecter et atténuer ses effets. Les opérateurs politiques et les éditeurs confirmaient qu’ils dépendaient davantage de la négativité et du sensationnalisme pour leur distribution en raison des changements algorithmiques récents favorisant les repartages.
En parallèle, un rapport interne de 2016 avait identifié que 64% de toutes les adhésions à des groupes extrémistes sur Facebook étaient dues aux outils de recommandation de la plateforme, principalement via les fonctions « Groups You Should Join » et « Discover ». Une task force créée par Chris Cox, alors Chief Product Officer, avait établi en 2017-2018 une corrélation entre la maximisation de l’engagement et la polarisation politique — et constaté que réduire la polarisation impliquait de réduire l’engagement.
L’expérience de contagion émotionnelle (2012)
Fait souvent oublié : dès 2012, Facebook avait mené une expérience de manipulation émotionnelle sur 689 003 utilisateurs sans leur consentement éclairé. Pendant une semaine, l’entreprise avait réduit l’exposition de certains utilisateurs aux contenus positifs de leurs amis, et d’autres aux contenus négatifs, puis mesuré si cela modifiait leur propre comportement expressif. Résultat : la contagion émotionnelle via le fil d’actualité était mesurable. L’étude a été publiée dans PNAS en 2014, déclenchant une plainte formelle d’EPIC auprès de la FTC pour pratiques commerciales trompeuses.
Ce qui est prouvé. Facebook savait, en interne, que ses algorithmes amplifiaient la désinformation, la polarisation et le contenu émotionnellement négatif. L’entreprise a documenté ces effets dans ses propres rapports. Des correctifs ont été proposés par ses propres équipes d’intégrité. La direction a systématiquement arbitré en faveur de l’engagement — et donc du revenu publicitaire — au détriment de l’intégrité informationnelle. Ce n’est pas une hypothèse : c’est la conclusion directe des documents internes rendus publics.
5. Outils actuels 2024-2026 — LLMs, médias synthétiques et dark patterns
LLMs et micro-ciblage politique
La convergence des grands modèles de langage et des données comportementales crée une capacité théorique nouvelle : la génération automatisée de contenu persuasif personnalisé à grande échelle. Des chercheurs de PNAS Nexus ont démontré en 2024 que des publicités politiques reformulées par GPT-3 et ChatGPT pour correspondre aux profils de personnalité OCEAN des cibles étaient perçues comme plus persuasives que des publicités génériques. La possibilité de créer ce que les chercheurs appellent une « machine de manipulation hautement scalable » qui cible les individus en fonction de leurs vulnérabilités uniques sans intervention humaine est techniquement démontrée.
Cependant — et c’est une nuance essentielle — les études les plus rigoureuses mesurant le changement réel d’attitude (et non la persuasion auto-déclarée) produisent des résultats plus modestes. L’étude de référence de Hackenburg et Margetts (PNAS, juin 2024), déployée à grande échelle avec intégration en temps réel de données démographiques dans les prompts GPT-4, conclut que les messages générés par le LLM étaient globalement persuasifs, mais que le micro-ciblage personnalisé n’offrait pas d’avantage statistiquement significatif par rapport aux messages non ciblés. Des études ultérieures (PNAS, mai 2025) confirment cette tendance : les LLMs sont approximativement aussi persuasifs avec ou sans personnalisation.
Comme le note le Reuters Institute dans une analyse de 2025 : les inquiétudes autour de l’IA générative et des élections ont été exagérées au regard des preuves disponibles. Il est actuellement plus facile de déployer à grande échelle les méthodes traditionnelles de persuasion politique que des méthodes basées sur les LLMs. La menace principale des LLMs en politique n’est peut-être pas le micro-ciblage mais la réduction massive du coût de production de contenu persuasif générique — et la possibilité future d’interactions multi-tours avec des chatbots qui pourraient s’intégrer dans le processus délibératif des citoyens.
Médias synthétiques : deepfakes à l’échelle industrielle
Le volume de vidéos deepfake partagées en ligne aurait explosé, passant d’environ 500 000 en 2023 à potentiellement 8 millions en 2025 selon les estimations du Service de recherche du Parlement européen — une multiplication par seize en deux ans. En 2025, les deepfakes de voix clonées et de personas visuelles sont devenus un risque récurrent dans les contextes électoraux.
Cas documentés récents : lors de l’élection présidentielle irlandaise de 2025, un deepfake a montré le futur vainqueur retirant sa candidature, accompagné de faux extraits de journaux télévisés nationaux « confirmant » l’information — diffusé quelques jours avant le vote. Aux Pays-Bas, environ 400 images synthétiques ont été utilisées pour attaquer des adversaires politiques. En Ukraine, en mars 2022, un deepfake du président Zelensky appelant les Ukrainiens à se rendre a été diffusé après le piratage du site d’une agence de presse — identifié comme probable opération de désinformation russe.
Le problème n’est pas seulement la tromperie directe. Les chercheurs observent un effet de second ordre plus insidieux : les deepfakes génèrent plus d’incertitude que de crédulité. Ils érodent la confiance dans l’ensemble du contenu en ligne, créant un environnement où le « déni plausible » devient une arme : tout contenu réel mais politiquement gênant peut être rejeté comme « probablement un deepfake ». C’est le concept de « dividende du menteur » — l’existence même de la technologie protège les menteurs.
Dark patterns et suppression algorithmique
Au-delà du contenu synthétique, les mécanismes de manipulation incluent les dark patterns d’interface (designs délibérément conçus pour orienter les comportements — consentement par défaut, friction asymétrique, urgence artificielle) et la suppression algorithmique de l’émergence organique. Ce dernier point est crucial pour les entrepreneurs et créateurs de contenu : les algorithmes de distribution des plateformes ne sont pas neutres. Ils favorisent structurellement le contenu qui maximise le temps passé sur la plateforme, au détriment du contenu informatif qui pourrait conduire l’utilisateur à agir hors-plateforme.
6. Cas européens documentés — Amesys et la surveillance industrielle française
Amesys : de la surveillance massive sous Kadhafi aux poursuites en France
Le cas Amesys est le cas européen le plus rigoureusement documenté de vente de technologies de surveillance à des régimes autoritaires. En 2007, Amesys (alors filiale du groupe Bull) a vendu au régime de Mouammar Kadhafi un système de surveillance des communications nommé « Eagle GLINT » pour environ 25 millions de dollars. Ce système n’était pas un outil de surveillance ciblée : les documents marketing d’Amesys, publiés par WikiLeaks, présentaient explicitement une offre d’interception « légale ou massive » — distinguant les deux modes et proposant les deux. Le mode massif permettait la recherche et surveillance globale de tout le trafic internet, l’archivage sur un an, et une vue synthétisée de l’ensemble du réseau.
En août 2011, des journalistes du Wall Street Journal ont découvert dans les bureaux saccagés des services de renseignement libyens à Tripoli un centre de surveillance Eagle opérationnel. Des victimes entendues par la justice française de 2013 à 2015 ont décrit avoir été arrêtées pour leur activité internet, puis détenues, interrogées et torturées. L’une d’elles, arrêtée fin 2009 — bien avant le soulèvement — suggère que le système était utilisé par les services de sécurité libyens dès cette date.
Le volet judiciaire est toujours en cours. En juin 2021, l’ancien PDG d’Amesys Philippe Vannier a été mis en examen pour « complicité d’actes de torture ». Trois dirigeants de Nexa Technologies (entité ayant repris les activités d’Amesys après la revente par Bull) ont été mis en examen pour « complicité d’actes de torture et de disparitions forcées » concernant la vente d’une version améliorée du système, « CEREBRO », au régime du président Sissi en Égypte. En novembre 2022, la Cour d’appel de Paris a confirmé les mises en examen d’Amesys et de ses dirigeants.
Le cas Amesys n’est pas un cas isolé dans le paysage français. Le groupe Qosmos a fait l’objet d’enquêtes pour des ventes similaires à la Syrie de Bachar el-Assad. Thales, via sa filiale de renseignement, opère sur des marchés de surveillance gouvernementale. L’industrie française de la surveillance numérique est un secteur structuré, historiquement toléré voire encouragé par les gouvernements successifs sous couvert de diplomatie commerciale.
France 2017 : Macron et le ciblage agrégé — le contrepoint légal
Le cas français offre un contrepoint instructif au modèle Cambridge Analytica. Pour la campagne présidentielle de 2017, Emmanuel Macron a fait appel à Liegey Muller Pons (LMP), startup fondée par trois Français qui s’étaient rencontrés en 2008 comme volontaires de la campagne Obama aux États-Unis. L’entreprise avait déjà contribué à la campagne Hollande en 2012. Macron les a contactés début 2016, alors que le projet En Marche était encore préparé en secret et qu’aucune base de données n’existait.
La contrainte réglementaire comme facteur structurant. Le droit français interdit le ciblage électoral au niveau individuel — pas de fichiers de listes électorales accessibles, pas de bases de données comportementales achetables comme aux États-Unis. Les stratèges de campagne ont donc opté pour un ciblage par groupes géographiques plutôt que par profils psychologiques individuels. C’est une différence fondamentale avec le modèle Cambridge Analytica.
Les outils déployés :
Le logiciel « Cinquante + Un » découpait la France en 67 000 zones correspondant aux bureaux de vote, croisait les données sociodémographiques INSEE avec les résultats électoraux depuis 2004 via un algorithme d’inférence écologique (méthode Gary King), pour produire une cartographie rue par rue des zones de conquête, des abstentionnistes mobilisables et des indécis. Pas de profilage psychométrique individuel — mais une résolution géographique fine.
L’opération fondatrice, « La Grande Marche » (mai 2016), a mobilisé plusieurs milliers de bénévoles qui ont fait remplir un questionnaire de 8 questions ouvertes. Environ 25 000 questionnaires ont été remplis et analysés par le logiciel de sémantique Proxem pour extraire les thèmes et les préoccupations dominantes par territoire. Cette base a servi simultanément à construire le programme et à définir la stratégie de communication — Macron a lui-même qualifié le programme initial de « diagnostic » plutôt que de programme classique.
La campagne nationale de porte-à-porte a touché 300 000 foyers. Toutes les interactions avec les électeurs étaient enregistrées et analysées sémantiquement pour extraire les mots-clés qui résonnaient. Du marketing automation a également été déployé : du 18 au 21 avril, un message vocal pré-enregistré a été diffusé à plusieurs millions d’abonnés téléphoniques — ce qui a valu à la campagne un rappel de la CNIL.
Sur le volet défensif, l’équipe Macron avait anticipé le risque de piratage (les #MacronLeaks, attribués par les services français et américains au GRU russe). La contre-mesure était simple mais efficace : l’équipe avait délibérément inondé ses propres systèmes de faux documents, de sorte que les hackers ont perdu un temps considérable à trier le vrai du faux. Le dump de 20 000 emails a atterri sur PasteBin quelques heures avant le blackout médiatique de 44 heures imposé par la loi électorale française — neutralisant l’essentiel de l’impact.
Pourquoi ce cas compte. La campagne Macron 2017 démontre deux choses. D’abord, que le cadre réglementaire (CNIL, interdiction du ciblage individuel) produit un effet structurant réel : il force un modèle de ciblage agrégé, moins intrusif que le profilage psychométrique individuel de Cambridge Analytica. Ensuite, que malgré cette contrainte, la sophistication data reste significative — 67 000 zones analysées, analyse sémantique automatisée, marketing automation de masse. Ce n’est pas de la manipulation au sens Cambridge Analytica, mais c’est de l’ingénierie du consentement au sens large. La distinction entre les deux réside dans le cadre juridique, pas dans l’intention. Et ce cadre juridique, en France, a fonctionné comme garde-fou — un point rarement souligné dans le débat public.
Le spectre européen : de l’opacité italienne à la régulation espagnole
Italie — Casaleggio Associati et le M5S : la plateforme comme parti. Le cas italien est le plus structurellement abouti en Europe. Le Mouvement 5 Étoiles, fondé en 2009 par le comique Beppe Grillo et l’entrepreneur web Gianroberto Casaleggio, a été conçu dès l’origine comme une expérience d’ingénierie sociale via les réseaux. Casaleggio, issu du marketing web, avait compris la possibilité d’utiliser les réseaux pour former et manipuler le consentement — il a d’abord expérimenté dans l’intranet de sa propre entreprise avant d’étendre l’expérience à l’échelle nationale via les réseaux sociaux (Meetup, puis Facebook).
Le M5S était structurellement contrôlé par une entreprise privée, Casaleggio Associati, qui possédait et opérait la plateforme de vote interne « Rousseau », le blog de Grillo, et un réseau de sites interconnectés (TzeTze, La Cosa, La Fucina). Une enquête de BuzzFeed News a découvert que le blog de Grillo, les sites du parti et les sites « d’information » liés partageaient les mêmes adresses IP ainsi que les mêmes identifiants Google Analytics et AdSense — un ancien employé de Google Ads a comparé ce réseau aux sites de fake news pro-Trump opérés depuis la Macédoine. Des enquêtes journalistiques italiennes (Jacopo Iacoboni, La Stampa) ont détaillé dans deux ouvrages (L’Esperimento et L’Esecuzione) comment Casaleggio contrôlait le blog de Grillo et planifiait les campagnes du mouvement, y compris l’introduction de techniques de programmation neurolinguistique au sein du groupe parlementaire M5S.
Le M5S a également été accusé d’être une source de désinformation et de propagande pro-Kremlin — des enquêtes ont tracé le réseau d’information du mouvement, partant du blog de Grillo et des réseaux sociaux du M5S, jusqu’aux sites gérés par Casaleggio Associati, qui diffusaient régulièrement des contenus anti-vaccins, des théories conspirationnistes et des narratifs alignés sur les intérêts russes. Le tout sous couvert de « démocratie directe » — un label que les analyses internes ont révélé être largement cosmétique : aucun choix stratégique n’était laissé aux militants, les décisions étant systématiquement imposées par le haut.
Allemagne — le FDP et les messages contradictoires. Le cas allemand offre un exemple documenté de micro-ciblage à messages divergents. Le parti libéral FDP a été identifié comme ayant montré aux personnes intéressées par les sujets environnementaux qu’il ferait davantage pour le climat, tout en promettant simultanément aux voyageurs fréquents qu’il ne soutiendrait aucune mesure réglementaire climatique. C’est l’application classique du micro-ciblage pour promettre des choses contradictoires à des audiences séparées — impossible à détecter sans accès aux bibliothèques publicitaires des plateformes. En parallèle, une étude académique sur 4 091 publicités Facebook pendant les élections nationales en Autriche, Italie, Allemagne et Suède a montré que le micro-ciblage systématique restait minoritaire en 2017-2018 dans ces pays, à l’exception notable de la Suède où la majorité des publicités étaient micro-ciblées.
Sur le volet surveillance, le débat sur l’utilisation de Palantir Gotham par les polices régionales a occupé l’été 2025 en Allemagne. Le Land de Hesse avait déployé le logiciel, déclenchant une opposition politique basée sur l’argument de la souveraineté technologique : un politicien régional a explicitement déclaré qu’il serait erroné de créer une nouvelle dépendance dans un secteur fondamental de l’État en achetant un logiciel Palantir.
Hongrie — l’ingérence transfrontalière intra-UE. Le cas hongrois illustre un phénomène rarement discuté : l’ingérence électorale entre États membres de l’UE. La Hongrie de Viktor Orbán est documentée comme ayant activement promu des candidats dans les élections d’autres pays européens. Lors des élections parlementaires slovaques de 2023, des publicités non étiquetées comme politiques ont été diffusées par des comptes hongrois pendant la période de silence électorale. Un compte gouvernemental hongrois a également diffusé des publicités sur l’immigration illégale avant des élections en Pologne, en Italie et en Allemagne, vues par des millions de citoyens. Ce type d’opération transfrontalière tombera sous le coup du Règlement européen sur la publicité politique une fois effectivement appliqué — mais illustre d’ici là une zone grise exploitable.
Espagne — acte de régulation directe. En mai 2024, l’Agence espagnole de protection des données (AEPD) a ordonné une interdiction temporaire du lancement des outils « Election Day Information » et « Voter Information Unit » de Meta avant les élections européennes. C’est l’un des rares actes de régulation directe d’un État membre contre une plateforme en contexte électoral — un précédent qui pourrait servir de modèle.
Pays-Bas — opacité Palantir. Des demandes d’accès à l’information rendues publiques en 2025 ont révélé que la police néerlandaise utilisait apparemment des outils Palantir depuis 2011, l’arrangement n’étant devenu public qu’à travers ces procédures de transparence. Europol aurait utilisé Palantir Gotham avant de mettre fin à cet arrangement.
La Commission européenne elle-même. Détail rarement mentionné : la Commission européenne aurait utilisé des publicités micro-ciblées en septembre 2023 pour promouvoir une nouvelle loi, en paramétrant le ciblage pour empêcher que les publicités soient montrées aux utilisateurs eurosceptiques. L’institution supposée réguler le micro-ciblage politique l’utilisait elle-même — un paradoxe qui en dit long sur la normalisation de ces pratiques.
Ce que montre le panorama européen. L’Europe n’est pas un espace protégé de l’ingénierie du consentement — c’est un espace où les formes varient. Le modèle italien (plateforme privée contrôlant un parti) diffère du modèle allemand (micro-ciblage contradictoire via Facebook Ads), du modèle hongrois (ingérence transfrontalière étatique), du modèle français (ciblage agrégé sous contrainte CNIL) et du modèle espagnol (régulation réactive). Le RGPD et le DSA fournissent un cadre théorique, mais l’application reste inégale. Et quand l’institution régulatrice elle-même utilise les outils qu’elle prétend encadrer, la question de la crédibilité du cadre se pose.
7. Palantir — L’infrastructure de la convergence données-décision
Les produits : Gotham, Foundry, AIP
Palantir Technologies, cofondée par Peter Thiel et Alex Karp, opère trois plateformes principales. Gotham est conçu pour le renseignement et les forces de l’ordre — il identifie des connexions entre personnes, lieux et événements à travers des ensembles de données massifs. Foundry est l’outil commercial et gouvernemental d’intégration et de visualisation de données. AIP (AI Platform) est la couche d’intelligence artificielle qui permet l’intégration de données en temps réel pour la prise de décision automatisée sur le terrain, y compris le ciblage militaire.
Contrats publics traçables
Le périmètre des contrats publics de Palantir est documenté avec une précision croissante — souvent contre la volonté de l’entreprise.
Royaume-Uni (>£900M documentés) : Une enquête menée par The Nerve, publiée en février 2026, a identifié au moins 34 contrats passés et en cours avec au moins dix départements gouvernementaux britanniques, pour un minimum de 670 millions de livres. Ce montant exclut le contrat de 240,6 millions de livres attribué au ministère de la Défense en décembre 2025 par attribution directe (sans mise en concurrence), sous exemption de défense et sécurité. Le NHS Federated Data Platform (330 millions de livres sur sept ans, attribué en novembre 2023) connecte les données de jusqu’à 240 organisations du NHS via le logiciel Foundry. En septembre 2025, le MoD a signé un contrat de près de 750 millions de livres pour l’intégration de l’IA dans les systèmes de décision militaire, de planification et de ciblage des forces armées britanniques. Le total documenté dépasse désormais 900 millions de livres — et The Nerve note que le chiffre réel est probablement supérieur, de multiples contrats restant non-reconnus ou lourdement caviardés.
États-Unis / ICE : En avril 2025, ICE a attribué un contrat de 30 millions de dollars à Palantir pour développer « ImmigrationOS », une plateforme de surveillance conçue pour rationaliser l’identification et l’appréhension de personnes ciblées pour l’expulsion, suivre les « auto-déportations » en quasi temps réel, et optimiser la logistique des expulsions. Palantir fournit des systèmes à ICE depuis 2013 (FALCON, Investigative Case Management). Plus récemment, l’outil ELITE (Enhanced Leads Identification & Targeting for Enforcement) cartographie les cibles potentielles de déportation, génère des dossiers individuels et attribue un score de confiance sur l’adresse actuelle de la personne — en puisant dans les données Medicaid et d’autres bases gouvernementales. En février 2026, le Contrôleur de la ville de New York a formellement demandé au conseil d’administration de Palantir de commander une évaluation indépendante des risques en matière de droits humains, notant que l’expansion de la collaboration avec ICE/ERO constituait un renversement de la position que l’entreprise avait prise en 2020 lorsqu’elle avait décliné ces contrats pour des raisons de risque d’enforcement disproportionné.
OTAN : L’Alliance atlantique a sélectionné Palantir pour son Allied Command Operations — le centre de commandement opérationnel de l’alliance — pour faciliter la prise de décision et la planification militaire. Ce choix a été interprété comme un revers pour la France, qui promeut depuis des années la souveraineté technologique européenne.
Controverses structurelles
Quatre points méritent attention :
Revolving doors : En 2025, Palantir a embauché quatre anciens fonctionnaires du MoD britannique, dont en septembre un ancien directeur de la politique, quelques jours après son départ du ministère. Le MoD a imposé des restrictions sur ses nouvelles fonctions. Le débat parlementaire du 10 février 2026 aux Communes a questionné le rôle de Peter Mandelson, dont le cabinet Global Counsel représentait Palantir alors qu’il servait comme ambassadeur britannique aux États-Unis.
Contrôle actionnarial : Palantir dispose d’une structure de gouvernance à contrôle insider qui limite la capacité des actionnaires externes à influencer la direction. Le Contrôleur de New York a explicitement cité cette structure comme raison de demander une supervision indépendante.
Conflits d’intérêts : Stephen Miller, architecte principal de la politique d’immigration de l’administration Trump, détient une participation financière substantielle dans Palantir — un conflit d’intérêt potentiel souligné par l’American Immigration Council.
Tension entre discours et pratiques : Palantir présente ses outils comme protégeant les citoyens contre les « intrusions inconstitutionnelles dans la vie privée par l’État ». Le CEO Alex Karp se décrit comme « engagé dans le soutien aux valeurs progressistes ». Mais la trajectoire documentée — de la déclaration de 2020 refusant les contrats ICE/ERO à l’attribution de ImmigrationOS et ELITE en 2025 — indique une évolution substantielle vers une implication plus profonde dans l’enforcement migratoire.
Fait vs. hypothèse. Faits documentés : les contrats listés ci-dessus sont traçables dans les registres publics. Les montants, les attributions directes, les revolving doors et les conflits d’intérêts sont documentés par des enquêtes journalistiques (The Nerve, Washington Post, 404 Media) et des demandes institutionnelles (Comptroller NYC, Parlement britannique). Hypothèse étayée : l’agrégation de ces contrats crée une position systémique dans l’infrastructure informationnelle des démocraties occidentales. La question de savoir si Palantir utilise cette position pour influencer la politique — au-delà de simplement la servir — est une question ouverte. Les preuves documentent une capacité, pas nécessairement une intention.
8. Conclusion à trois niveaux
Niveau 1 : Comprendre le mécanisme
La fabrication du consentement en 2026 opère sur trois couches superposées. La couche héritée (filtres Chomsky-Herman) structure toujours la production de l’information : propriété concentrée, dépendance publicitaire, sources institutionnelles. La couche algorithmique (post-2010) individualise le filtrage via des systèmes d’engagement optimisés pour la colère et la polarisation — avec des preuves internes que les plateformes connaissent et acceptent ces effets. La couche émergente (2023+) ajoute la génération synthétique à coût marginal quasi nul : deepfakes industriels, contenu persuasif automatisé, chatbots pouvant potentiellement s’intégrer dans les processus délibératifs des citoyens.
Ces trois couches ne sont pas des alternatives — elles se renforcent mutuellement. Le contenu synthétique est distribué par les algorithmes d’engagement, qui opèrent dans un paysage médiatique structuré par la concentration de la propriété. Comprendre une couche sans les deux autres, c’est ne voir qu’un tiers du mécanisme.
Niveau 2 : Se défendre individuellement
Quatre principes opérationnels pour des lecteurs qui pensent par eux-mêmes :
Identifier la source du signal, pas seulement le message. Qui finance la plateforme qui vous montre ce contenu ? Quel est le modèle économique ? Si le contenu est gratuit, c’est que votre attention est le produit. Cela ne rend pas le contenu faux — mais cela vous dit quel type de contenu sera systématiquement favorisé (engageant, polarisant, émotionnel).
Ralentir le cycle de réaction. Les algorithmes optimisent pour la réaction immédiate. La réaction immédiate est le mécanisme même par lequel le filtrage opère. Introduire un délai — même de quelques heures — entre l’exposition à un contenu et la réaction est le geste le plus simple et le plus efficace pour court-circuiter le mécanisme.
Diversifier activement les sources. Le filtrage algorithmique crée des bulles informationnelles par construction. La contre-mesure est la diversification délibérée — y compris vers des sources avec lesquelles on est en désaccord. Lire les arguments de la position opposée dans leur forme la plus forte (pas leur caricature) est un exercice d’hygiène intellectuelle.
Distinguer fait, analyse et opinion. Tout au long de cet article, la distinction entre faits documentés et hypothèses étayées a été signalée. Appliquer cette discipline à chaque contenu consommé — est-ce un fait vérifiable, une analyse dérivée de faits, ou une opinion — réduit la surface d’attaque de la manipulation.
Niveau 3 : Implications investissement
La fabrication du consentement n’est pas seulement un sujet politique — c’est un secteur économique. Trois axes de lecture pour l’investisseur :
L’ad-tech comme infrastructure de surveillance. Le modèle publicitaire programmatique (Google, Meta, The Trade Desk) repose sur la collecte et la monétisation de données comportementales. C’est le même substrat technique qui alimente le micro-ciblage politique. Le secteur est exposé à un risque réglementaire croissant (EU AI Act, Digital Services Act, potentiel Digital Markets Act enforcement), mais génère des marges exceptionnelles tant que la régulation reste incomplète. Position : pas un achat thématique — un risque à monitorer dans les positions existantes ad-tech.
Les data brokers comme marché gris de l’influence. Acxiom (maintenant LiveRamp), Oracle Data Cloud (fermé en 2024), Epsilon, et des dizaines d’acteurs plus petits constituent l’infrastructure invisible du ciblage. La valeur de ces entreprises réside dans leur capacité à agréger, relier et monétiser des profils individuels — exactement la capacité qui alimente les opérations d’influence. La régulation européenne (RGPD, ePrivacy) crée un avantage compétitif pour les acteurs conformes, mais le marché américain reste nettement moins contraint.
Palantir comme position thématique sur la data-souveraineté. Palantir occupe une position unique : c’est le seul acteur coté qui opère simultanément dans le renseignement militaire, le law enforcement, la santé publique et le secteur commercial, avec une intégration AI native (AIP). Le titre a gagné plus de 396% en 2025 — une valorisation qui intègre déjà une prime considérable.
| Métrique | Observation |
|---|---|
| Revenus gouvernement | 55% du CA en 2024 — forte dépendance au cycle politique US |
| Contrats UK documentés | >£900M, expansion rapide sous gouvernement Starmer |
| Contrats EU | OTAN, polices régionales (Hesse, Pays-Bas), tensions souveraineté |
| Risque ESG/droits humains | Demande formelle d’audit indépendant (NYC Comptroller, fév. 2026) |
| Insider control | Structure de gouvernance limitant le pouvoir des actionnaires externes |
| Croissance commerciale | Push actif vers healthcare, finance, énergie — diversification du risque gouvernement |
Thèse investissement : Palantir est une position thématique sur la tendance structurelle de numérisation de la décision étatique — pas un endorsement de ses pratiques. Le titre est un proxy sur la probabilité que les gouvernements occidentaux continuent d’externaliser leur infrastructure data vers un fournisseur unique plutôt que de construire des capacités souveraines. La trajectoire actuelle (expansion UK, OTAN, ICE) va dans ce sens. Le risque est double : régulation européenne sur la souveraineté des données (qui pourrait créer un plafond de croissance EU), et risque réputationnel croissant qui pourrait affecter la rétention des talents et la croissance commerciale. À la valorisation actuelle, le titre price une exécution quasi parfaite — ce qui rend le risk/reward asymétrique pour une entrée nouvelle. C’est un dossier à comprendre et à suivre, pas nécessairement à acheter aujourd’hui.
Points clés
- Les cinq filtres de Chomsky/Herman (1988) n’ont pas disparu — ils se sont numérisés et individualisés. Le modèle de filtrage industriel est devenu un modèle de filtrage algorithmique opérant au niveau de chaque utilisateur.
- La manipulation structurelle de l’opinion est un phénomène documenté bien antérieur au numérique (COINTELPRO, Gladio, affaire de l’Observatoire). Le numérique a changé l’échelle et la vitesse, pas la nature du problème.
- SCL Group/Cambridge Analytica a transposé des techniques de psyops militaires dans 60+ pays vers les élections civiles. L’efficacité réelle du micro-ciblage psychographique reste débattue académiquement, mais la capacité technique est démontrée.
- Les Facebook Files prouvent — par documentation interne — que les plateformes connaissent les effets de polarisation et de désinformation de leurs algorithmes et choisissent de ne pas les corriger quand cela réduit l’engagement.
- Les LLMs sont persuasifs en agrégat mais le micro-ciblage personnalisé n’offre pas (encore) d’avantage statistiquement significatif. La menace principale est la réduction du coût de production de contenu persuasif, pas la précision du ciblage.
- Les deepfakes ont franchi un seuil critique : ~8M de vidéos estimées en 2025 contre 500K en 2023. Leur effet principal n’est pas la tromperie directe mais l’érosion de la confiance (« dividende du menteur »).
- Amesys (France) a vendu des systèmes de surveillance massive au régime Kadhafi et au régime Sissi. Les dirigeants sont mis en examen pour complicité de torture. Le cas illustre la complicité industrielle européenne dans la surveillance autoritaire.
- La campagne Macron 2017 (Liegey Muller Pons, logiciel « Cinquante + Un », analyse sémantique Proxem) démontre que le cadre CNIL force un modèle de ciblage agrégé par zone — moins intrusif que le profilage psychométrique individuel. La contrainte réglementaire fonctionne comme garde-fou structurant, pas seulement comme formalité.
- Palantir détient >£900M de contrats UK documentés, opère dans le renseignement OTAN, et construit ImmigrationOS pour ICE. Sa position est systémique — ce qui en fait à la fois un risque démocratique et une position d’investissement thématique sur la data-souveraineté.